因為剛換了一份具有挑戰性的新工作,有好一陣子沒有發文了,雖然手上有幾個在進行的學習或者project,但進度都還沒到可以發表文章的程度。剛好最近工作上有一個之前沒碰過的問題,花了一些時間做處理,因此在這邊簡單地記錄一下。
問題敘述
在某個上班日的下午,筆者突然收到來自前端工程師的訊息,在跑CI process時GitLab Runner好像出了問題,導致pipeline fail了。經查詢後,發現是該Runner所在的VM disk 容量已達99.9%,已經不能夠再pull任何的image下來了。
GitLab Runner在執行CICD job時,會pull許多暫時的image來完成任務。在敝公司的每一台Runner中,都有一個固定於每日凌晨執行的cronjob來清除這些job產生出來的image、volume以及build cache等。因此在一開始,筆者懷疑cronjob是否根本沒有如期執行,從而往system log去查看,想確認cronjob執行的狀況。
不料,cronjob的確有在指定的時間執行。但僅從system log並沒有辦法得知更詳細的資訊——例如執行前的硬體容量多少?執行後多少?如果cronjob確實有做容量的清除,那麼硬碟滿載的情況下大都在一天中的何時發生?SRE該如何即時得知這些訊息?
可以從以上資訊得知,Gitlab Runner所在的虛擬機缺乏監控設施,導致我們沒有辦法即時、有效地獲得系統狀況,進而做出適合的判斷與解決方案。因此,建立系統的可觀測性便是開始解決問題的第一步。
建立系統可觀測性:收集系統指標
敝公司的其他專案使用Prometheus + Grafana作為主要監控工具之一,又筆者只需要監控Linux中的系統指標,Prometheus已有現成的exporter可以做使用。綜合考量下,筆者在每一台Runner起了node_exporter的container以收集host-level的metrics,再使用Grafana去收集這些指標,繪製成可視化圖表。
在這邊提一個小題外話,筆者先前也有自己實作過host-level的metrics exporter,只不過當時單純地認為,如果使用container部署這個服務,那麼觀察的指標不就只限於container裡面了嗎?事實上,在萬物皆檔案(Everything is a file)的Linux當中,我們可以在/proc、/sys等目錄找到CPU、Memory、Disk相關的資訊,因此如果想觀察host的指標,就只需要把host的檔案目錄掛載到container中就可以了!
node_exporter的官方GitHub中就給了docker-compose.yaml的最佳範例:
---
version: '3.8'
services:
node_exporter:
image: quay.io/prometheus/node-exporter:latest
container_name: node_exporter
command:
- '--path.rootfs=/host'
network_mode: host
pid: host
restart: unless-stopped
volumes:
- '/:/host:ro,rslave'
在監控與告警皆架設完成後(這部分其實還有一些細碎的小東西可以談,例如告警的閾值怎麼設?要監控哪些指標?因為怕偏離重點,先暫且不提),筆者發現,在上班時間,每一台Runner的硬碟佔用量已達全部容量的70~80%,約是400多GB左右,那自然是撐不到在半夜執行的cronjob。此外,即便筆者手動執行完docker system prune -a -f這個可以清除unused container、image以及building cache的指令,也只清除了80G左右的容量。
基本上,每一台Runner所在的虛擬機就只有裝Runner這個應用程式,而且部署方式還是container,怎麼會佔用快要400GB的容量呢?
最後,透過資深同事的幫助,以下列指令發現這龐大的體積來源來自於Docker下面的overlay2資料夾。光是這個資料夾就佔用了300多GB。
du -ch --max-depth=1 /datadrive/docker/
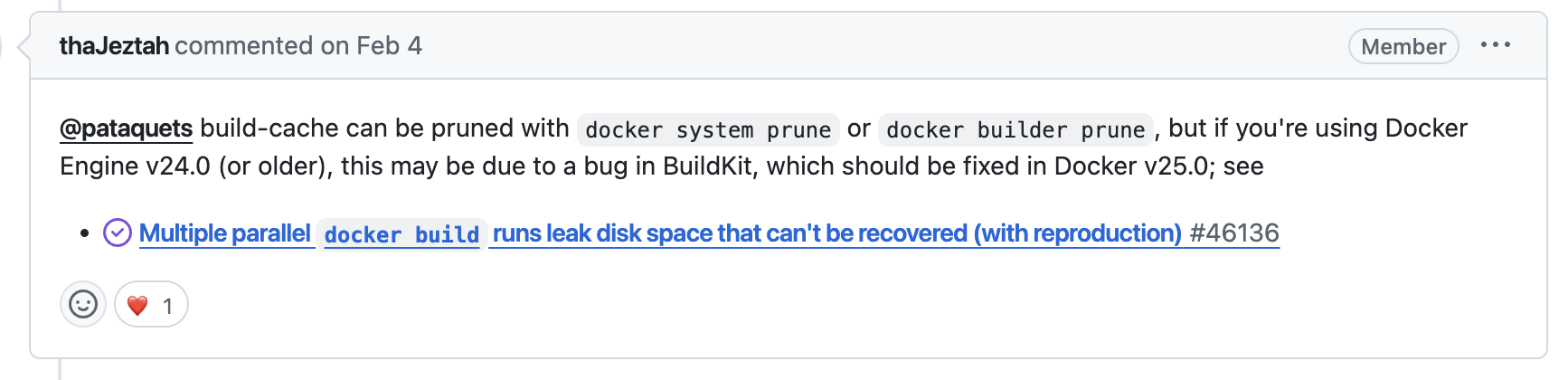
Docker v25後才修復的bug
難道是連docker system prune都沒有辦法清理overlay嗎?錯了,docker system prune這個指令就是拿來清除任何暫停的container、沒有在使用的network, images, build cache。之所以會沒辦法完全清除,是因為這是Docker v25以前的一個bug(剛好敝公司使用的版本是v24…)
docker system prune
WARNING! This will remove:
- all stopped containers
- all networks not used by at least one container
- all dangling images
- unused build cache
Are you sure you want to continue? [y/N] y
採取行動
定位問題後,首先採取的步驟當然是將Docker進行升級,基本上確認過change log中沒有什麼比較大的breaking change,在升級過程中並不會碰上什麼問題。
# Upgrade to the latest version
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# check docker version and status
docker version
sudo systemctl status docker
不過,在升級到最新版本v27.3.1之後,執行docker system prune -a -f還是沒辦法把overlay2裡面的build cache給清除!在查詢各個技術論壇的討論後,可能原因有以下:
-
有可能是目前Docker底下的檔案目錄不完整,導致Docker engine發生非預期的損壞,在這個推論下,也不推薦直接刪除龐大的
docker/overlay2資料夾,因為它屬於整個docker filesystem的一部份,不確定僅刪除這個資料夾會不會造成引擎的損壞。 -
我們都知道Docker image是由一層一層的layer所組成,除了能用來區分唯獨層/可寫層(container),透過共用layer的技術來減少image實際所佔用的硬體空間。我們在
Dockerfile撰寫的指令就是一層層的layer,在pull image時,也能看見layer會依序的被pull下來,最後成就一個完整的image。
但是,當image 在創建時,假設實體硬碟已經滿了,image理所當然就會創建失敗,那麼在硬碟滿了之前、已經pull下來的layer呢?它們還是會存在於overlay2的資料夾當中,只是Docker engine已經沒有辦法追蹤到他們,造成這些沒有被創建完成的layer就無法透過Docker指令進行刪除了。
因此,筆者總結,一開始應是因為Docker本身的bug導致layer無法被完整刪除,又先前發生過幾次硬碟被填滿的狀況,導致許多沒有被創建完成的孤兒layer被留在overlay2資料夾中,即便Docker升級也無法被正確刪除。
既然這些孤兒layer已無法被拯救,最好的方法便只剩下重啟Docker engine,來讓Docker重新組織並管理新的檔案系統。
# DANGER, this will reset docker, deleting all containers, images, and volumes
systemctl stop docker
systemctl stop docker.socket
sudo rm -rf /datadrive/docker
systemctl start docker
systemctl start docker.socket
重啟Docker以後,會看到Docker檔案系統已經重新長了回來,狀態和功能也都一切正常。之後,在使用docker system prune指令時,就能正確清除overlay2資料夾裡所用不到的layers了。
後記
這次算是比較幸運,Gitlab Runner本身就是一個stateless的服務,不太需要去規劃資料的備份與保存,如果下次再遇到類似的事情,又是stateful的服務的話,可能就還需要多加一個資料備份的步驟,避免刪除整個Docker檔案系統而發生無法挽回的憾事。
本篇來不及講到的指標監控和告警設置的部分,也是筆者認為非常有趣的部分,就等到下一篇文章再與各位分享。