iTHOME自2022年舉辦第一場SRE Conference,今年已是第三屆,而這也是我從AppWorks School後端班畢業後參加的第一場技術研討會。做為一個剛從後端領域跨足到SRE的新手來說,此行不僅看到各個公司在導入SRE以及kubernetes的評估與考量之外,透過工作坊的動手做,了解了kubernetes絕對不是僅止於撰寫yaml檔而已。感嘆著這條路的水果然很深之外,更因為還有許多地方可以探索而感到非常興奮。
此篇文章主要是參加幾場演講下來的速記,因為有些演講的筆記較多,可能會分為兩到三篇來撰寫,同時也會以每場演講作為主題劃分。
Data Architecture and Analysis about OpenTelemetry Observability
講者:蘇揮原 (Mars), TrendMicro
講者一開始先從趨勢科技的自有產品 - Vision One作為引言,當產品從"Security Tool"逐漸壯大成一個"Cybersecurity Platform"時,那我們該怎麼去管理這些服務?我們可以從下面那張圖看到,Vision One透過單一的平台服務來偵測、預防與應對來自不同地方的資安攻擊與風險,並搭配自動化與人工智慧來落實全方位的資安管理。

那麼,有這麼多的服務都運行在單一的平台上面,勢必得做好管理。講者在這裡提到了兩個名詞:Proactive monitoring以及Observability。我會佔用以下小小的篇幅來大致講述這兩個名詞概念。
許多針對監控相關的產品網站都提到了proactive monitoring的概念,而我在Datadog官方網站上找到proactive monitoring的定義為: Proactive monitoring is key to flagging potential issues with your applications and infrastructure early, enabling you to respond quickly and reduce downtime.
意思即是,主動監控是及早發現應用程式與基礎架構潛在問題的關鍵,它幫助我們能快速針對這些問題做出反應,減少server downtime。
在這裡講者也針對proactive monitoring拋出了一個概念:在用戶發現前先發現問題。
另一方面,與Proactive Monitoring相互輝映的名詞及是Observebility,以我自己的邏輯來看,我們已經了解到了Proactive Monitoring的好處,那我們該怎麼去做到實際上的監控?第一,我們的系統必須具備可以被觀測(Observable)的能力;再來,透過這些觀測到的資訊,它應該要能幫助我們了解目前系統或者服務的狀態,且我們能有效利用這些資訊來做出適當的判斷。
在這裡也一併附上CNCF(Cloud Native Computing Foundation)對於Observability的解釋:
Observability is a system property that defines the degree to which the system can generate actionable insights. It allows users to understand a system’s state from these external outputs and take (corrective) action.
Observable systems yield meaningful, actionable data to their operators, allowing them to achieve favorable outcomes (faster incident response, increased developer productivity) and less toil and downtime.
Consequently, how observable a system is will significantly impact its operating and development costs.
OpenTelemetry Concept & Data Architecture
鋪陳到這裡總算進入到正題了!如同上面提到的,監控即是指我們怎麼去利用手上拿到的資料,做出最適當的判斷,在用戶發現之前提早偵測問題去解決。
OpenTelemetry(簡稱OTel)是雲原生的可觀測性框架,協助開發者蒐集並導出Observability Signal(Metric, Log, Trace),他提供標準化的API及SDK來降低蒐集數據的困難度,進而讓開發者們能更方便地進行後續的資料分析以了解系統的性能與行為。
編按: 為了做到軟體服務的可觀測性(Observebility),服務必須要能夠發出如Metric, Log, Trace等資料,在這裡,我們稱做這些資料為Observability Signal,OpenTelemetry即是透過蒐集這些資料,把這些資料轉送到後端,進而達成監控的目的。
既然我們已經了解了OpenTelemetry的功能與目的,那麼就可以把它與其他監控工具如Prometheus, Grafana等串聯在一起,建構完整的Data Architecture。
在這邊講者有秀出在公司實踐過的系統架構,在這篇筆記就不多加贅述,在這部分其實講者有引入幾個在設計這種data pipeline時可以有的幾個思路:
- 當資料量非常龐大的時候,要怎麼做才能有效率地進行資料查詢與分析? > 可能需要尋找一個適當的資料倉儲?
- Throughtput: 系統要可以掌握大量的資料擷取(data ingestion)與查詢(queries)
- Analysis: 可以根據不同的情境輕鬆地產出對應的資料分析,甚至這些資料要能餵給LLM進行機器學習
- Cost: 成本控制
綜合以上的思路與考量,我們可以選擇OLAP Data Warehouse來有效處理大量資料並做對應的數據呈現,至於為什麼選擇OLAP,請看下個章節的介紹。
OLAP Data Warehouse & ClickHouse
每種資料庫進行數據儲存的方式不盡相同,不同的儲存方式都有其適合的情境,當資料量一大、系統負載不斷增加時,要選擇何種的儲存方式就顯得非常重要。
OLAP(Online Analyticla Processing, 線上分析處理)通常用於儲存和處理大量資料,以下簡單列點幾項OLAP的特性以及擅長處理之情境:
- 當大多數的請求都是以讀取資料為主時
- 查詢時間非常快速
- 可以從資料庫中快速讀取很大筆的行資料
- 高吞吐量(throughtput)
- 不太需要資料庫的transaction特性
- 資料需要可以被篩選或聚合,讓資料庫的查詢結果比來源資料還要小
綜合以上,當資料庫儲存資料的結構上採取Column-Based時,就可以很好地實現或應對以上情境,這是因為資料採取分欄位儲存的方式,當我們只需要提取某些欄位的資料時,我們只需要讀取特定的欄位,而不需要讀取整張資料表。
{
"id": [1, 2, 3],
"name": ["John Doe", "Jane Smith", "Mike Johnson"],
"age": [30, 25, 28],
"email": ["johndoe@example.com", "janesmith@example.com", "mikejohnson@example.com"],
"occupation": ["Software Developer", "Data Analyst", "Product Manager"]
}
基於OLAP以上的特性,它時常與Data Warehouse結合使用,來增強Data Warehouse的分析能力與效能。而我們可以結合OLAP servers 以及Data Warehouse來完整從資料收集一直到產生儀表板的流程。
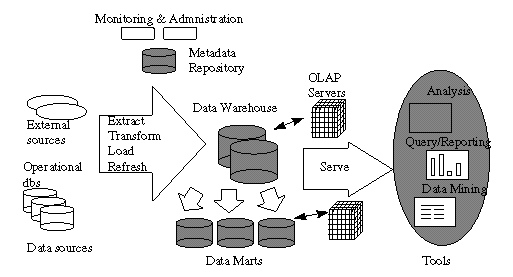
透過上面的示意圖,我們也可以說從一開始的information sources到Data Warehouse這一段,採用的是ETL(Extract, Transform, Load),主要著重在技術邏輯(Technical Logic);而從Dataware House一直到用戶端產生儀表板或者數據分析的這一段,採用的是ELT(Extract, Load, Transform),這邊我自己的理解是先把資料撈出來,再根據用戶端的商業邏輯與需求,將資料進行轉換並產生適當的圖表,因此相對於前半段,這邊主要是根據商業邏輯(Business Logic)做出的流程。
用於OLAP情境的資料庫系統非常多,在這場演講中,講者特別介紹了ClickHouse這項產品,因此我稍微搜尋了一下ClickHouse的介紹以及優勢。
ClickHouse® is a high-performance, column-oriented SQL database management system (DBMS) for online analytical processing (OLAP). It is available as both an open-source software and a cloud offering.
作為一個column-based 的資料庫管理系統,除了上述提到的column-based資料庫應該具備的優勢與特性以外,他也支援OpenTelemetry的exporter - 沒錯,就是前面那個章節提到的雲原生框架;在性能方面,ClickHouse透過分布式查詢、並行(Concurrency)處理、資料壓縮等方式,來完成更有效率的資料庫查詢,同時它也支持基於ANSI SQL standard的查詢語言。
ClickHouse Keeper
ClickHouse 資料庫支援分散式與複製資料的功能,其方法是透過將資料切成多個片段(shards),而這些資料片段則會分布在不同的資料庫節點上,而多個節點則可以集合成一個叢集(cluster)。 ClickHouse的官方網站聲稱"ClickHouse Keeper is a drop-in replacement for ZooKeeper",在ClickHouse cluster的不同節點之間,它確保集群中的各個節點可以保持一致性且能互相協調工作,且相較於Zookeeper,對於同樣的資料量來說,它在Memory, CPU等效能方面的表現都較Zookeeper還要來得好。
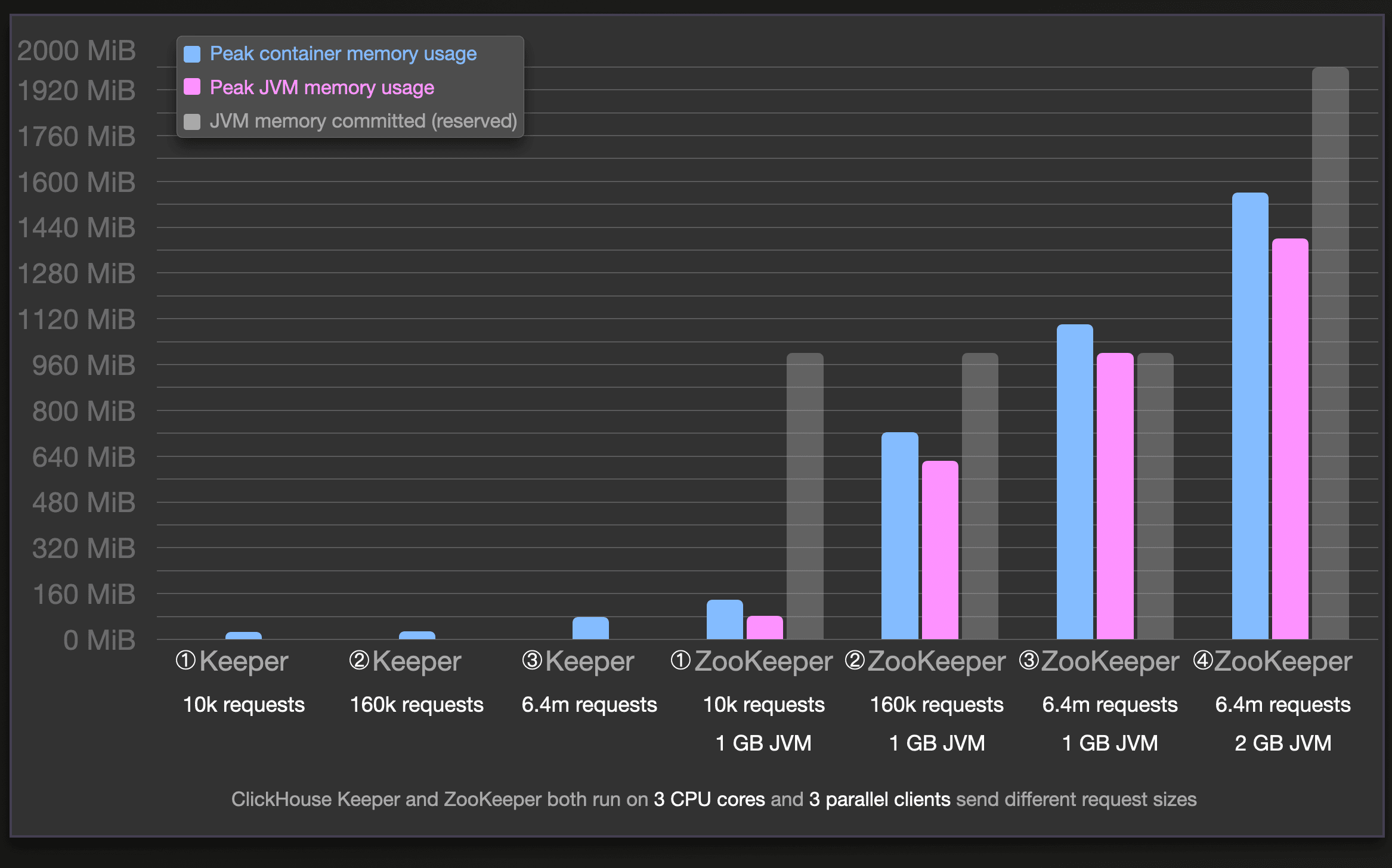
ClickHouse Keeper使用兩種不同的方式來做讀/寫操作。在叢集當中,每個節點上面都會有一個local table,當我們在寫入資料時,則會直接把資料寫入某個節點上面的local table。但當我們要做讀操作時,則會先經過一個叫做Distributed Table的虛擬表,它會把各個節點上面的local table資料給匯集起來,這樣即使我們不個別探訪每個node上面的local table,也能讀取到完整的資料。
System Design (ClickHouse as storage)
綜上所述,ClickHouse協助我們處理需要大量查詢、大量讀取資料的情境,因此,當我們要設計一個Monitoring pipeline時,可以結合前面說到的ETL, ELT的觀念,並將原先收集資料的Prometheus取代成ClickHouse: Kafka + OpenTelemetry (ETL, 使用Kafka處理data streaming並使用OpenTelemetry蒐集資料) -> ClickHouse Cluster(ELT) -> Grafana (呈現資料)
心得
在AppWorks School時的個人專案剛好就做了一個監控系統,在其中的幾場面試中,也常被問到該如何處理大量寫入、大量讀取的情境。而在實際的業務需求上,常聽到的監控系統不外乎就是Prometheus串聯Grafana來做使用,但當需要監控的資料量非常龐大時,要怎麼提升處理資料的效能便是一件值得團隊來思考的問題。在這場演講中學習了不同的資料處理方式,以及一個團隊在面臨效能瓶頸時,是如何在不斷地調整架構與測試中,找到最適合團隊的設計。
講者最後還有提到ClickHouse的另一個功能 - Feature Stores,它用來儲存、查詢、管理機器學習的特徵,但在這部分本文章就不花篇幅敘述,可以參考官方ClickHouse的介紹影片:
Reference
趨勢科技 - Trend Vision One https://www.trendmicro.com/zh_tw/business/products/one-platform.html
OLAP 和 OLTP 有什麼區別? https://aws.amazon.com/tw/compare/the-difference-between-olap-and-oltp/
What is OLAP and how can you use it in data warehousing? https://www.linkedin.com/advice/0/what-olap-how-can-you-use-data-warehousing-skills-data-management-9fpnc
ClickHouse Document https://clickhouse.com/docs/en/intro
Powering Feature Stores with ClickHouse https://clickhouse.com/blog/powering-featurestores-with-clickhouse
踏上 MLOps 之路:從 Applied Data Scientist 到 MLOps 的轉變與建構:Day 18 Feature Store https://ithelp.ithome.com.tw/articles/10324947?sc=rss.iron