前言
開始第一份工作以後,真切體會到容器化技術的強大與方便之處,工作中處處離不開container,但自己又真的懂它幫我們做了什麼事情嗎?為了更了解容器化技術的底層原理,那不如就自己來做一個container看看好了!
CNCF的開發專案大多由Golang寫成,同時做為一個語法簡潔、易讀、擁有強大併發處理能力的語言,我相信使用它來建構容器等系統工具是個好選擇,因此本文將會以Golang作為程式碼的範例。
什麼時候會需要用到container?
要回答這個問題,我們先來看看Docker官方對於container的解釋:
A container is a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another.
一年前我還是個連docker都沒聽過的程式小白,當我想把網站部署到雲端上時,我的作法就是直接把github的程式碼clone到我的機器上,直接加裝任何程式碼所需要的套件及程式語言。現在回想起來,直接在機器上面運行程式碼實在有太多風險了:錯誤的程式碼可能造成系統損壞、資源過度消耗,甚至是運行的程式碼可能包含惡意程式而導致安全漏洞……除此之外,直接在機器上加裝一堆套件也讓環境變得又髒又亂,更別說在多人協作的開發場合中,建置環境時也很常發生「為什麼程式碼在你的電腦可以跑,我的不行?」的惱人狀況。
基於以上痛點,我們再回頭來看container的定義:container是一個標準的軟體單位,它把程式碼以及所需要的環境與依賴項目給一起打包,讓整個應用程式可以快速地被搬運到另一個運算環境並且可靠地運行。有了container,我們不但可以避免直接運行程式碼的風險,開發環境與生產環境也都會變得乾淨許多。
那麼,container是怎麼做到的?以上面的定義來看,container做到了環境打包、隔離,這兩個功能對應到的linux技術即是filesystem以及namespace,除此之外,host也需要去管理與限制container可以使用的資源,而這部分就屬於cgroups的範疇。因此,為了更了解container的底層原理,以下將會敘述這三個技術是怎麼成就container的。
Namespace
當我們運行一個container時,會發現在container當中,我們只能看到在container裡運行的process,如果先前對container有一些認識,大概會知道container是使用命名空間來做到隔離。
我們直接來看Linux manual page中對於Namespace的解釋:
A namespace wraps a global system resource in an abstraction thatmakes it appear to the processes within the namespace that theyhave their own isolated instance of the global resource. Change to the global resource are visible to other processes that are members of the namespace, but are invisible to other processes.
Namespace透過把global的系統資源封裝,使得處在同個namespace的processes可以看到所處namespace的資源;如果是在別的namespace的process,就也只能看到自己所處的namespace資源,而看不到其他namespace的資源與processes,透過這樣的方式,不同namespace的processes們看起來就像被「隔離」了!
不過,這只限於被關在container裡面的process,對於host來說,他可以看到每個container裡面所運行的process,只是,以同一個process來說,從host視角所看見的PID,和container裡面的PID又會是不相同的。
在筆者撰寫文章的當下(2024年),Linux總共有八種namespaces,分別是Cgroup, IPC, Network, Mount, PID, Time. User, UTS。簡單來說,每個namespace的種類名稱就代表它隔離了甚麼樣的資源。因為等等我們會需要使用Golang建立namespace,在這邊附上Linux manual table對於各個namespace的介紹,待會實作時我們也會使用到這些namespace:
Namespace Flag Page Isolates
Cgroup CLONE_NEWCGROUP cgroup_namespaces(7) Cgroup root directory
IPC CLONE_NEWIPC ipc_namespaces(7) System V IPC,
POSIX message queues
Network CLONE_NEWNET network_namespaces(7) Network devices,
stacks, ports, etc.
Mount CLONE_NEWNS mount_namespaces(7) Mount points
PID CLONE_NEWPID pid_namespaces(7) Process IDs
Time CLONE_NEWTIME time_namespaces(7) Boot and monotonic
clocks
User CLONE_NEWUSER user_namespaces(7) User and group IDs
UTS CLONE_NEWUTS uts_namespaces(7) Hostname and NIS
domain name
cgroup
現在,我們擁有了多個獨立運行的namespace,cgroup則幫我們實現了namespace之間的資源分配與限制。cgroup的全名叫做Control Group,是Linux Kernel的功能之一,它將processes組織到一個有階層的(hierarchical)組別當中,藉此來監控並限制資源的分配,來對CPU, memory等資源做更精細的控制。
cgroup把每種可以控制的資源定義為一個子系統(subsystem),每個子系統都會和kernal的其他模組配合來完成資源控制,例如,CPU子系統會和process scheduling module配合來完成CPU的資源配置。
所以,以CPU和Memory資源為例,我們的cgroup filesystem架構可能會長得像下面這張圖片:
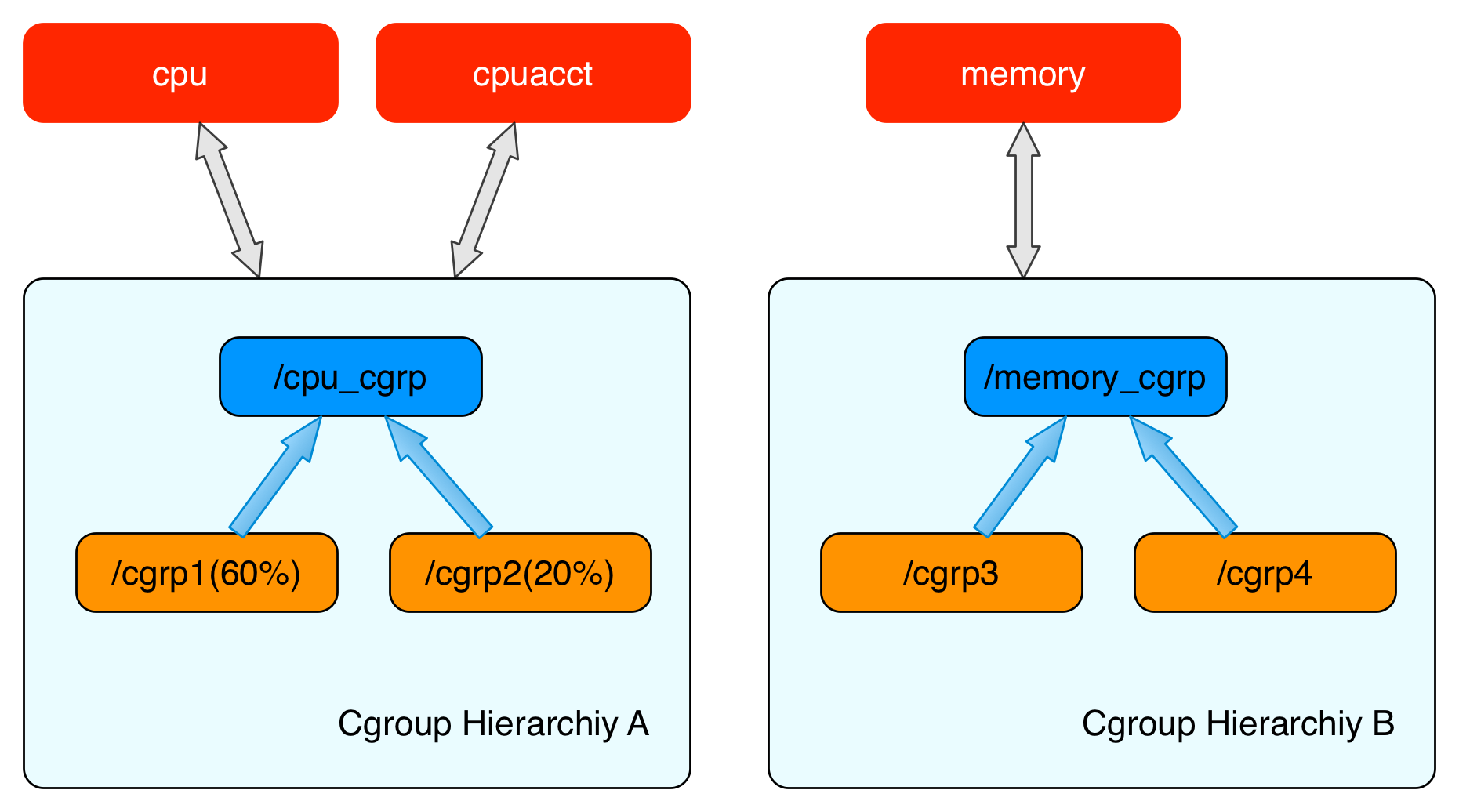
可以看到, Cgroup Hierarchiy A使用了cpu以及cpuacct這兩個subsystem,在Hierarchiy A這個階層中,最上層的/cpu_cgrp作為根節點,可以想像成是它握有這個階層的總資源,並再進一步地將資源分配給它下面的子節點,
因此我們可以說,根節點負責:
- 資源分配:因為根節點擁有整個階層的資源,它會按照訂定的策略將資源分配下去。
- 管理cgroup:根節點會監控每個子節點的資源使用情況,確保資源分配的正確性。
- 設定屬性與限制:根節點可以設置屬性與限制,而繼承根節點的那些子節點必須遵守。例如,根節點可以設置RAM的使用上限,而這個限制會影響所有繼承它的子節點。
而繼承它的子節點則必須遵守這些配置與限制。因此,子節點(在這裡,就是/cgrp1和/cgrp2)才是這個階層當中的實體cgroup,負責將分配到的資源再分配給process來做使用。
為了要讓使用者可以自行定義各種資源配置,kernal會把cgroup以檔案系統的形式暴露出來,這個文件系統叫做Virtual File System,它讓使用者可以透過編輯、創建文件,就可以控制process的資源使用。
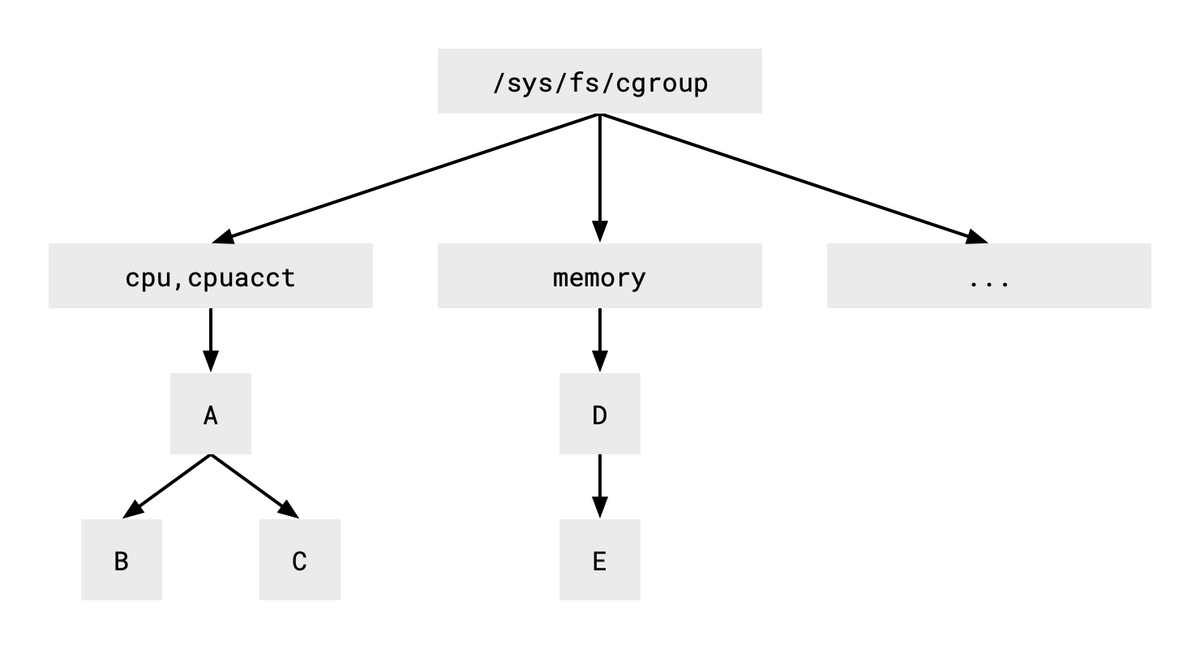
大家常提到的cgroup v1和v2的比較,主要也是在檔案系統的管理上的差異。cgroup v1會針對不同的subsystem創建不同的資料夾,如果想要使用不同的subsystem,我們就必須切換到不同的資料夾去建立cgroup;但在v2中,所有的subsystem都會合併到同一個掛載點(通常會是/sys/fs/cgroup),我們只要進入這個資料夾,就可以看到所有subsystem的配置與控制文件,由此可見,v2相較於v1,簡化了管理配置與管理檔案的流程。
chroot檔案系統隔離
一般說到container的檔案系統技術,第一時間會想到的應該是Union Filesystem(聯合檔案系統),不過這次實作並沒有引入這項技術(XD),所以這邊就不多加贅述,不過非常推薦大家閱讀小賴老師的鐵人賽文章,以原理搭配實驗講解得非常清楚:Day 07: 什麼是 overlay2?
題外話結束,那麼這個小章節就來聊聊我們要怎麼幫檔案系統做到隔離。可能大家看到這段的第一個想法會是:要做到隔離,namespace不就可以幫我們做到了嗎?但實際上,namespace只是控制裡面的process可以看到甚麼,雖然不同的namespace中的process看不見彼此,但是process還是可以訪問host的檔案系統!若是如此,不僅並沒有完全做到隔離環境,還有可能會導致安全上的問題。
簡單來說,chroot改變了特定process即其child process的根目錄,接著,process就只能夠訪問新的根目錄以及下面的子目錄,不能夠對這個根目錄之外的檔案進行讀取或者修改,這樣就實現了container與host間的檔案系統隔離了。
實際上要怎麼去製作container所使用的root directory,我們在下一章節會使用Golang來進行實作。
小小後記
本章節所提到關於namespace, cgroup, filesystem的技術,因為篇幅有限,加上本次主題旨在如何透過Golang實作container,因此在內容部分僅點到為止,沒有更深入的探討。尤其是cgroup,可以探討的概念、原理與使用方法(例如cgroup怎麼再往下分配process資源,以及實際如何使用VFS來管理cgroup資源,都還來不及講到),我認為還蠻值得再花一篇文章介紹它的(先挖坑給自己跳)。
Reference
Docker: Use containers to Build, Share and Run your applications
Linux manual page: namespace(7)
The Linux Kernal Documentation: CGROUPS
Five Things to Prepare for Cgroup v2 with Kubernetes